再構成可能なアクセラレータを搭載した効率的なエッジAIチップ

{% module_block module "widget_1689266637355" %}{% module_attribute "child_css" is_json="true"...

人工知能(AI)は、多くのアプリケーションのルールを変えつつあります。EdgeCortixのチームは、物体やパターンを認識するためのAIモデルのトレーニングを行い、入力されるデータストリームに対してそのモデルを使ってAI推論を実行します。サイズ、重量、電力、時間があまり問題にならない場合は、データセンターやクラウドベースのAI推論でもよいかもしれません。しかし、リソースに制約のあるエッジデバイスでは、異なるテクノロジーが必要です。より多くのデバイスでエッジAI推論を実現するには?エッジにおけるAI推論の違いとIPがどのように対応しているかを見ていきましょう。
ほとんどのAI推論は、ある種のニューラルネットワークのアーキテクチャに依存しています。根本的なレベルでは、ニューラルネットワークは積和演算方式であり、複数のレイヤにまたがる複数の並列構造のデータに対して一連の重み付け係数を付与する計算を実行します。
ごく単純なニューラルネットワークモデルでなければ、AI推論のワークロードと従来型のプロセッサコア、メモリ、インターコネクトでの処理とでは、根本的なミスマッチが存在します。汎用CPUでは並列での計算処理が不十分で、(AI推論の状況では)不要な演算のオーバーヘッドが大きすぎたりと、推論ワークロードに適していません。
GPUは、多数の小さなコアと構成可能なインターコネクトを備えているため、より適合性が高いのですが、それでもまだ、エッジコンピューティングのアプリケーションに対して大きな効率性の問題が2つあります。まず、高性能なGPUはリソースを大量に消費するため、十分なAC電源と強制空冷が必要ですが、エッジプラットフォームでは利用できないことが多々あります。また、AI推論タスクにおけるGPUハードウェアの使用率は低く、通常30~40%程度で、これは使える計算リソースの半分以上を捨てているようなものです。
実行ユニット、メモリ、インターコネクト間の複雑な相互作用により、1秒間にテラまたはペタ演算(TOPSまたはPOPS)で表される演算は、AI推論の効率についてほとんど意味をもちません。GPUをスケールアップして演算量を増やせば、推論性能の不足を解消できるかもしれませんが、それではより多くのリソースを消費するだけです。
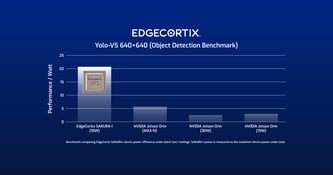
AI推論の効率をより適切に評価するには、スループットとエネルギー消費量を1つの指標で示す必要があります。IPS/W (Inferences per second per watt) は、比較を正規化し、AI推論IPの真のスケールを示します。EdgeCortixは、あるエッジAI推論のシナリオにおいて、GPUベースの構成に比べて16倍ものIPS/Wの効率向上が可能であることを実証しています。

どのようにして桁違いの効率化を実現しているのしょうか。ニューラルネットワークの推論IPを考える上で、3つのアーキテクチャパラメータに着目した結果が「効率化」です。
これらの要素をすべて考慮すると、ニューラルネットワークIPは、エッジでより多くのことを実現することができます。消費電力が少ないため、バッテリーの持ちが良くなり、より長い時間使用することができます。
新たな方法論は、リアルタイム・アプリケーションへの道を開きます。また、与えられたスペースに1ワット、1秒あたりの推論数を増やすことで、エッジデバイスはより複雑なAIモデルを処理できるようになり、効率の悪いアプローチでは不可能だった機能を実現することができるようになります。
より効率的で定義付けが可能なニューラルネットワークのIPについてはお分かりいただけたと思うので、本題に戻りましょう。「より多くのデバイスでエッジAI推論を実現するには?」
大まかに定義すると、エッジコンピューティングは、処理が行われる場所に近いところに、より多くの処理能力を備えます。どのような作業が必要で、どのようなSWaP(サイズ、重量、電力)が利用できるかが、フォームファクタの選択の決め手となります。
スケーラビリティとランタイムで再構成可能という特性を備えた、EdgeCortixのニューラルネットワークIPは、ハイエンドマイクロコントローラからFPGAアクセラレータカードにおけるシステムオンチップ設計に至るまで、さまざまな形態を取ることができます。EdgeCortixのソリューションは2つのコンポーネントから構成されています。1つ目はコンパイラおよびソフトウェアフレームワークであるMERA で、2つ目は、ランタイムで再構成可能なAI処理コアである Dynamic Neural Accelerator IP (DNA IP) です。 EdgeCortixは、この2つのコンポーネントを SAKURA SoCに実装し、デバイスの形態ですぐに使えるエッジAIチップとして提供しています。
エコシステム・パートナーの協力を得ることで、エッジAI推論は様々な形態に実装が可能です。FPGAアクセラレータカード は、 スマート・マニュファクチャリング や スマートシティのアプリケーション など、スペースや消費電力に余裕がある場合に、柔軟な実装を可能にします。SAKURAのSoCは、 防衛、 5G通信、ロボットやドローンのアプリケーション で、サイズや重量が懸念される場合、カスタムボード設計に適した、より小さなパッケージで推論を提供することができます。また、オートモーティブ・センシング のアプリケーション向けに設計されたカスタムSoCなど、よりカスタマイズ性の高い製品も選択肢の一つです。

もう一つの利点としては、EdgeCortixのテクノロジーを使えば、AIモデルの専門家がハードウェア実装の詳細を理解していなくても、効率的で高性能なエッジAI推論を扱えるということが挙げられます。GPU ベースの実装のみを扱ってきた研究者は、そのサイズから、大幅な再設計を行わない限りエッジデバイスに適用することができなかったことに対し、このテクノロジーは大いに受け入れられることでしょう。
現在、効率の悪いAI推論プラットフォームを使っている方でも、EdgeCortixの技術を簡単にお使い頂くことが可能です。MERAはGitHubのリポジトリからダウンロード可能です。また、すぐにお使い頂けるPCIeカードもあります。一つは、SAKURA SoCを搭載したEdgeCortixのカードで、もう一つは、Intel Agilex FPGAにビットストリームをロードしたAI推論パックを搭載したBittWare社のFPGA カードです



