
AIが牽引するソフトウェア定義のヘテロジニアス・コンピューティング時代

{% module_block module "widget_1688008903796" %}{% module_attribute "child_css" is_json="true" %}{%...

AI推論の話題の多くは、できるだけ早く多くの処理を提供することに焦点が当てられています。データセンターのように実質的に無制限の電力と冷却を備えた施設では、GPUベースの大きなシステムを実装することが可能です。しかし、データセンター以外の場所(広義では「エッジ」)にある組み込みシステムの制約が加わると、サイズ、重量、電力、利用率を考慮してスケーリングされた、より効率的なエッジAIチップが不可欠となります。EdgeCortix Dynamic Neural Accelerator (DNA) プロセッサアーキテクチャは、カスタムASICやFPGAベースの多くのアプリケーションで、AI推論の高速化ソリューションを提供します。
AIワークロードの多くは、膨大な数の乗算演算を必要とし、主にTOPSで測定されます。数個のコアしかないCPUアーキテクチャから、多数のコアを持つ並列処理アーキテクチャに移行すると、通常、AIモデルの実行が高速化されます。多くのAIアプリケーションでGPUベースの実装が定着したのはそのためです。しかし、モデルが複雑化するにつれて、GPUを含むAI推論ハードウェアの過剰に設計された並列性は、ほとんどのAI推論モデルの利用率を低下させ、スペースとエネルギーを浪費させる結果となりました。
AI推論に特化したプロセッサコアを最適化することは、効率を向上させるための論理的なステップです。特定のAI推論モデルや類似モデルの類を実行する最適化されたエッジAIチップを設計することは可能です。しかし、並列度はAIモデルによって異なるため、設計者は、モデルが変わるとハードコーディングされた最適化が上手く回らなくなることにすぐに気づきます。
EdgeCortixのDNAプロセッサ・アーキテクチャは、自社のエッジAIチップ「SAKURA-I」のバックボーンとなり、ライセンス可能なIPとしても提供されていますが、それとは異なります。ソフトウェアとハードウェアの協調設計により効率面での課題を解決し、様々な種類のハードウェア並列処理とソフトウェアコンパイルを組み合わせて、実行ユニット、メモリアクセス、データパスをワークロードに合わせて動的に再構成します。今回は、ランタイムで再構成を実現する上で、MERAコンパイラ がDNA IPとどのように連携しているかを詳しく紹介します。
性能は、再構成可能性がもたらすもう1つの基準となりますが、それだけではありません。アプリケーションによっては、同じスペースにより多くのTOPSを詰め込むことが重要な基準となる場合があります。すべてのAI推論問題で、最大限のスループットが求められるわけではありません。リコンフィギュレーションにより、DNA IPは、EdgeCortix SAKURA-I のようなエッジAI専用のチップに搭載されたり、サードパーティのFPGAベースのアクセラレータにビットストリームとして組み込むことで、各々のデバイスの重要な課題に見合ったレベルでAI推論処理を実行します。
GPUは強力なAI推論性能を特徴としていますが、効率性を犠牲にしており、30~40%しかそのリソースを活用していません。しかし、DNA IPは、ランタイムで再構成するツールを使用することで、あらゆるスケールにおいて80%以上の使用効率のままパフォーマンスの増減を実現します。DNA IPのパワーマネージメント機能により、設計者は不要な時のエネルギーを節約することができます。PyTorch、TensorFlow、ONNXなどの業界をリードするフレームワークを使ってワークステーションやサーバーで開発したモデルは、DNA IPが搭載されたエッジデバイスで簡単に実行が可能です。設計者は、ハードウェアIPレベルでの面倒な性能最適化作業から解放され、エッジデバイスを成功させるための基準を満たすことに全集中することができます。
MERAがランタイム構成の詳細を管理する一方で、設計者はDNA IPをアプリケーションに適したサイズにする方法を勘案します。ユーザーがDNA IPのライセンスを取得し、独自の用途に合わせたエッジAIチップを作成する際に必要な柔軟性を提供できるのが大きな特徴です。

全ての設計チームが、SoC設計をゼロから実行するための専門知識や時間を持っているわけではありません。 SAKURA-I は、DNA IPを内蔵したEdgeCortixの既製エッジAIチップで、ボードやシステム設計にすぐに対応できます。10Wの総消費電力プロファイルで最大40TOPSを実現し、多くのアプリケーションで5W程度の消費電力で使用可能です。EdgeCortixは、SAKURAをフルレングス、フルハイトのPCIe x16カードとロープロファイルのバージョンで提供しています。また、OEMボードに組み込むためのスタンドアロン部品としても利用可能です。
エッジAIは非常に細分化された市場であり、柔軟なソリューションが求められています。DNA IPのもう一つの使用例は、より高い柔軟性をターゲットとするFPGAベースのアクセラレーションカードで、GPUカードに取って代わり、しばしばサーバーを統合する機会を提供し、アプリケーションをデータセンターからエッジに移行させるのに役立ちます。EdgeCortix / BittWare / Intelの推論パックは、DNA IPを高性能なIntel® Agilex™ FPGAを搭載したBittWare IA-840FおよびIA-420Fカード用のすぐに使えるビットストリームとしてお届けします。
DNA IPとMERAの強力なコンビネーションで、ユーザーがAIアプリケーションを効率的に動かすために必要となるハードウェア固有の知識を減らすことができます。完全にカスタムメイドのSoCやマイクロプロセッサーが必要な場合は、半導体設計の専門知識を持つチームがDNA IPを利用して、独自のソリューションを構築することができます。推論パックは、GPUベースのカードに代わる、より多くの推論密度とアプリケーション開発者のためのスムーズなソフトウェア移行を実現するドロップインの代替品となります。
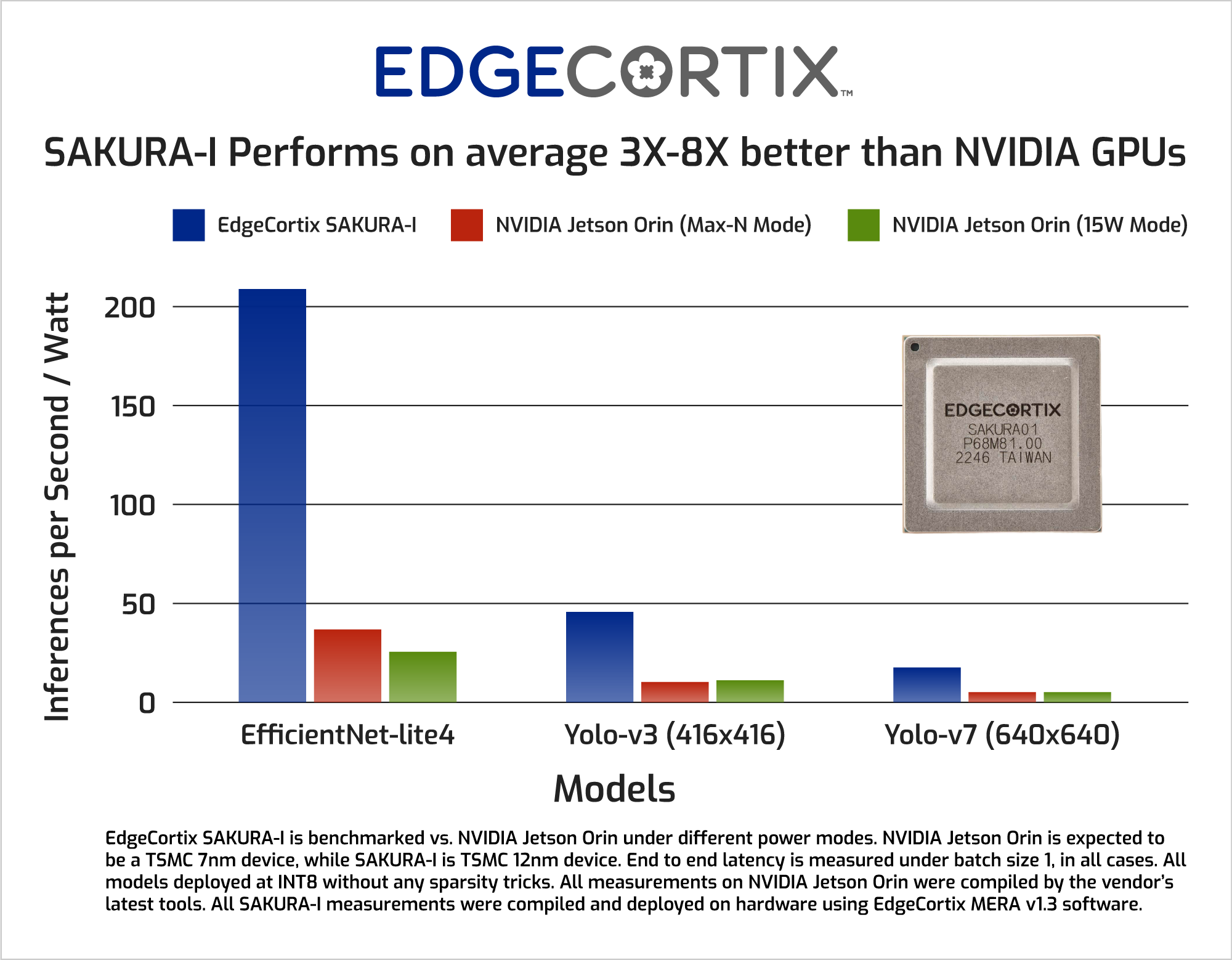
SAKURAは、ボードやシステムの設計者がすぐに使えるエッジAIチップとなります。SAKURA-Iは、同等のNVIDIA® Jetson AGX Orin™の実装よりも優れた性能/ワットを実現し、AGX Orinの30W構成に比べてYolo-V5の結果が10倍向上しています。近日中にリリースされるSAKURAの新バージョンでは、性能/ワット数のリードをさらに広げる予定です。
EdgeCortix DNAプロセッサの全てのユースケースの中心に「効率性」があります。その背後にあるのはランタイムで再構成可能というエッジAIチップの協調設計の戦略です。エッジAI処理の幅広いニーズに対して一つの実績があるIPをベースラインとして用いることで、市場投入までの時間とリスクを低減することが可能になります。



