










Connecting Edge AI Software with PyTorch, TensorFlow Lite, and ONNX Models

{% module_block module "widget_2c9de310-be51-4468-93fa-774c290569b3" %}{% module_attribute...

Much of the AI inference conversation focuses on delivering as many operations as quickly as possible. Massive GPU-based implementations can find homes in data centers with practically unlimited power and cooling. However, add some embedded system constraints found outside the data center – broadly defined as “the edge” – and more efficient edge AI chips scaled for size, weight, power, and utilization become mandatory. EdgeCortix’s Dynamic Neural Accelerator processor architecture (DNA) powers custom ASIC and FPGA-based acceleration solutions for AI inference in many applications.
Most AI workloads call for massive numbers of multiplication operations, often measured in tera operations per second (TOPS). Moving away from a CPU architecture with only a few cores to a parallel processing architecture with many cores usually speeds up AI model execution. It’s why GPU-based implementations took hold in many AI applications. But as models grow in complexity, overdesigned parallelism in AI inference hardware, including GPUs, results in poor utilization for most AI inference models, wasting space and energy.
Optimizing a processor core specifically for AI inference is a logical step to improve efficiency. It’s possible to design an optimized edge AI chip that runs a specific AI inference model or a class of similar models. Designers soon discover the degree of parallelism varies from AI model to model, and hard-coded optimizations can unravel when models change.
EdgeCortix’s DNA processor architecture, which forms the backbone of their SAKURA-I edge-AI chips and is also available as licensable IP, is different. Leveraging software and hardware co-design to solve efficiency challenges, it mixes various types of hardware parallelism with software compilation, reconfiguring execution units, memory access, and data paths dynamically to match the workload. Here’s a deeper look at how the MERA compiler works with DNA IP in achieving run-time reconfigurability.
Performance is another motive for reconfigurability – but it’s not the only one. Packing more TOPS into the same space is a criterion for some applications. Not every AI inference problem requires maximum, flat-out throughput. Reconfigurability sets the stage for DNA IP to handle inference processing inside dedicated edge AI chips like the EdgeCortix SAKURA-I or embedded as bitstreams on third party FPGA-based accelerators meeting critical challenges in devices:
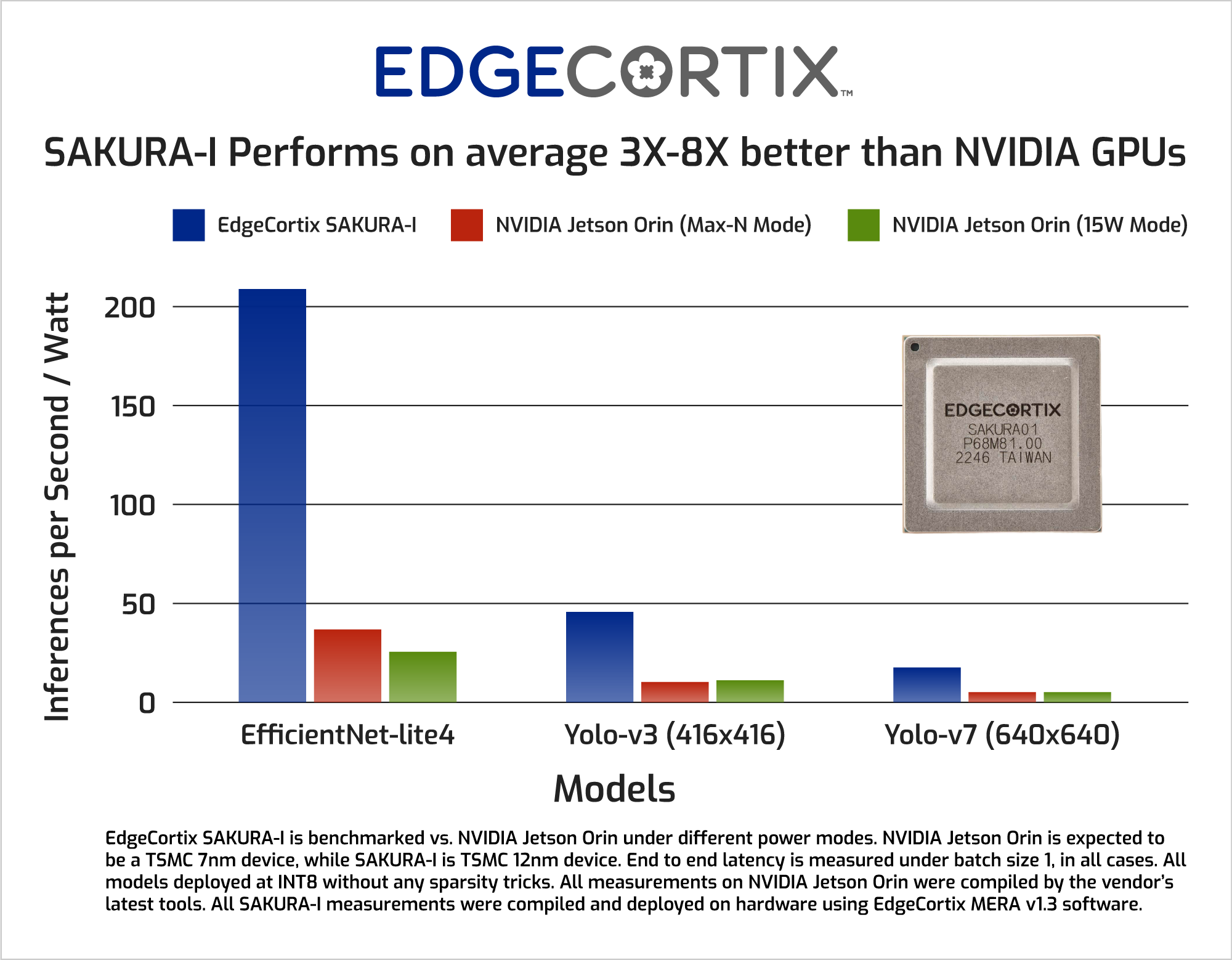
GPUs feature strong AI inference performance but sacrifice efficiency, hitting only 30 to 40%. DNA IP scales performance up or down at 80% or higher efficiency using the same tools for run-time reconfiguration at any scale. Power management features in DNA IP help designers conserve energy when not needed. Models developed on a workstation or server in industry-leading frameworks like PyTorch, TensorFlow, or ONNX can easily move into an edge device running DNA IP. Designers are freed from tedious performance optimization tasks at the hardware IP level and can concentrate on meeting all the criteria for a successful edge device.
While MERA takes care of the run-time configuration details, designers still control how to right-size DNA IP for an application. Key features provide needed flexibility when OEMs license DNA IP and create purpose-built edge AI chips for unique applications:

Not every team has the expertise or time to execute an SoC design from scratch. SAKURA-I is an off-the-shelf edge AI chip from EdgeCortix built with DNA IP and ready for board and system designs. It provides up to 40 TOPS (dense) in a 10W total power consumption profile, often using as little as 5W in many applications. EdgeCortix offers SAKURA on a full-length, full-height PCIe x16 card as well as low-profile versions. Alternatively, it can be a standalone part for design into an OEM board.
Edge AI is a highly fragmented market demanding flexible solutions. Targeting higher flexibility, another use case for DNA IP is in FPGA-based acceleration cards, replacing GPU cards and often creating the opportunity for server consolidation, helping move applications out of the data center and toward the edge. An EdgeCortix / BittWare / Intel Inference Pack configures DNA IP into ready-to-use bitstreams for BittWare IA-840F and IA-420F cards featuring high-performance Intel® Agilex™ FPGAs.
DNA IP and MERA are a potent combination, reducing the hardware-specific knowledge OEMs would otherwise need to power AI applications efficiently. If a fully customized SoC or microprocessor is required, teams with semiconductor design expertise can take DNA IP and craft their unique solution. The Inference Pack offers a drop-in replacement for GPU-based cards with more inference density and a smooth software transition for application developers.
SAKURA enables board and system designers with ready-to-use edge AI chips – with next-generation members of the SAKURA family in development at EdgeCortix today. SAKURA-I delivers better performance/watt than comparable NVIDIA® Jetson AGX Orin™ implementations, with a 10x improvement in Yolo-V5 results over a 30W configuration of AGX Orin. New versions of SAKURA coming soon will open the performance/watt lead further.
Efficiency, achieved with a co-design strategy behind run-time reconfiguration for edge AI chips, is central to all DNA IP use cases. Using one proven IP baseline across the scalability spectrum of edge AI processing presents opportunities to reduce time-to-market and risk.




